Ever tried building a RAG system that actually works for the all the different ways humans ask questions? After years of building and breaking retrieval systems at scale, I've found that most RAG failures happen at the query understanding level.
Here's the thing: not all queries are created equal. The reason your system hallucinates or gives garbage answers often has more to do with the question type than your vector DB settings or chunking strategy.
I've distilled RAG queries into 5 distinct patterns, each requiring different handling strategies. Understanding these will save your team months of confusion and help you diagnose issues before they become production nightmares. These are the most common patterns I've seen in RAG systems, but I don't claim they are the only ones.
- Synthesis queries: Straightforward factoid retrieval with light transformation
- Lookup queries: Require specific information retrieval, often with time/comparative elements
- Multi-hop queries: Need decomposition into sub-questions for complete answers
- Insufficient context queries: Questions your system should admit it can't answer
- Creative/generative queries: Where LLM hallucination is actually desired
Synthesis queries are the bread and butter of RAG systems - straightforward questions requiring basic factual retrieval and minimal transformation.
Examples:
- "What were our Q2 earnings?"
- "What's the maximum dosage for Drug X?"
- "When was our healthcare policy updated?"
💡 Key insight: Synthesis queries typically map directly to content in your knowledge base, requiring minimal inferencing from the LLM. These are where RAG truly shines.
These queries typically follow a predictable pattern:
- A clear, singular subject
- A specific attribute being requested
- No complex temporal or conditional elements
Engineering implication: For synthesis queries, retrieval precision matters more than recall. Your system needs to find the exact relevant information rather than gathering broadly related context.
I built a healthcare RAG system where we optimized specifically for synthesis queries by implementing a document-first chunking strategy. This increased our accuracy by 17% for straightforward factual queries while sacrificing performance on more complex questions - a tradeoff we explicitly made based on user behavior analysis.
Lookup queries introduce additional complexity through comparative elements, time components, or the need to process patterns. These often rely on aggregation over some attributes e.g. time, location and I recommend setting up a metadata index to support these queries.
Examples:
- "How did our healthcare costs compare between 2022 and 2023?"
- "What's the trend in side effect reporting for Drug X over the past 5 years?"
- "Show me all dividend-paying stocks that increased yield for 3 consecutive quarters"
Look for these patterns in lookup queries:
- Time-bound components ("during 2023," "over the past five years")
- Comparative elements ("compared to," "versus")
- Trend analysis requirements ("pattern," "trend," "over time")
Engineering implication: Lookup queries often require merging information from multiple documents or sources. Your RAG system needs strong reranking capabilities and potentially dedicated retrieval strategies e.g. text2sql and preprocessing the corpus to include tables which can be queried (h/t Dhruv Anand)
One approach I've found effective is implementing a two-phase retrieval:
- Fetch the core entities and facts
- Run a separate retrieval for the comparison elements
- Let the LLM synthesize both retrieved contexts
These are the questions that require breaking down into sub-questions, with each answer feeding into the next retrieval step.
Examples:
- "Which of our healthcare plans has the best coverage for the conditions most common among our engineering team?"
- "What investment strategy would have performed best in the sectors where we saw the highest growth last quarter?"
💡 Key insight: Multi-hop queries can't be solved with a single retrieval operation. They require decomposition, planning, and sequential execution.
Engineering implication: Your system architecture needs to support query planning and multiple retrieval steps. This often means implementing:
- A query decomposition module to break complex questions into simpler ones
- A retrieval orchestrator to manage multiple search operations
- A synthesis component to integrate findings from multiple retrievals
I remember debugging a financial RAG system that kept hallucinating on multi-hop queries. The root cause wasn't the retrieval system - it was the lack of a decomposition step. We implemented a simple query planning stage that improved accuracy by 32% for complex queries.
Some questions simply cannot be answered with the information available. The hallmark of a mature RAG system is recognizing these cases.
Examples:
- "What will our stock price be next quarter?"
- "Which unreleased drug in our pipeline will have the fewest side effects?"
- "How will changes to healthcare policy affect our costs in 2026?"
Engineering implication: You need to implement robust confidence scoring and thresholds for when your system should refuse to answer. This requires:
- Evaluating retrieval quality (not just semantic similarity)
- Assessing whether retrieved content actually addresses the query
- Implementing explicit "insufficient information" detection
One technique I've found effective is implementing a self-evaluation prompt after the RAG pipeline generates an answer:
Given the original query "{query}" and the retrieved context "{context}",
evaluate whether the generated answer "{answer}" is:
1. Fully supported by the retrieved context
2. Partially supported with some unsupported claims
3. Largely unsupported by the context
If the evaluation returns categories 2 or 3, we either refuse to answer or clearly indicate what parts of the response are speculative.
Some queries explicitly request creative generation where strict factuality isn't the primary goal.
Examples:
- "Draft a blog post about our healthcare benefits program"
- "Generate a sample investor pitch based on our financial performance"
- "Write a description of what our ideal drug delivery mechanism might look like"
💡 Key insight: For creative queries, LLM capabilities should be emphasized over retrieval, using the knowledge base as inspiration rather than constraint.
Engineering implication: Your system needs to:
- Identify when a query is creative rather than factual
- Adjust the retrieval-generation balance to favor generation
- Use broader, more diverse retrieval to spark creativity
- Preferably, implement different evaluation metrics for these queries
Don't expect users to tell you what type of query they're asking. Your system needs to detect this automatically. I've implemented a simple but effective query classifier that looks something like this:
def classify_rag_query(query: str) -> str:
"""
Classifies a query into one of the five RAG query types using Instructor for function calling.
"""
from instructor import patch
from pydantic import BaseModel, Field
class QueryClassification(BaseModel):
category: str = Field(
description="The query category",
enum=[
"synthesis",
"lookup",
"multi-hop",
"insufficient_context",
"creative"
]
)
confidence: float = Field(
description="Confidence score for the classification",
ge=0.0,
le=1.0
)
# Patch the LLM to enable structured outputs
patched_llm = patch(llm)
result = patched_llm.chat.predict_model(
model=QueryClassification,
messages=[{
"role": "user",
"content": f"Classify this query: {query}"
}]
)
return result.category
For effective RAG system evaluation, you need a test suite that covers all five query types:
| Query Type | Evaluation Metrics |
| Synthesis | Precision, Answer correctness |
| Lookup | F1 score, Completeness |
| Multi-hop | Reasoning correctness, Factuality |
| Insufficient context | Refusal rate, Hallucination detection |
| Creative | Relevance, Creativity metrics |
How often does your team debug RAG issues without first identifying the query type? Most teams I see spend weeks optimizing retrieval parameters when the real problem is a mismatch between query type and system design.
Next time your RAG system fails, ask: "What type of query is this, and is our system designed to handle this specific type?"
Originally published by Nirant Kasliwal, who builds RAG systems that don't embarrass your brand.
Thanks to Dhruv Anand and Rajaswa Patil for reading drafts of this.
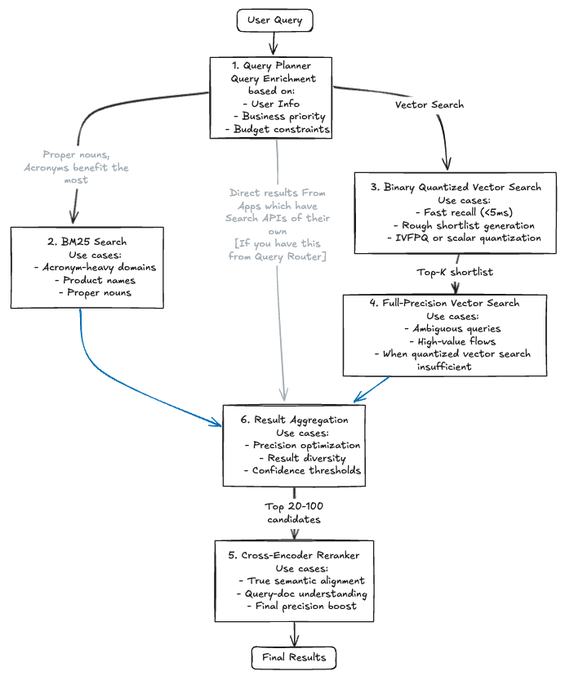 Figure: Retrieval stack architecture balancing cost, quality, and latency. Each layer maximizes relevance per dollar and enables debugging.
Figure: Retrieval stack architecture balancing cost, quality, and latency. Each layer maximizes relevance per dollar and enables debugging.