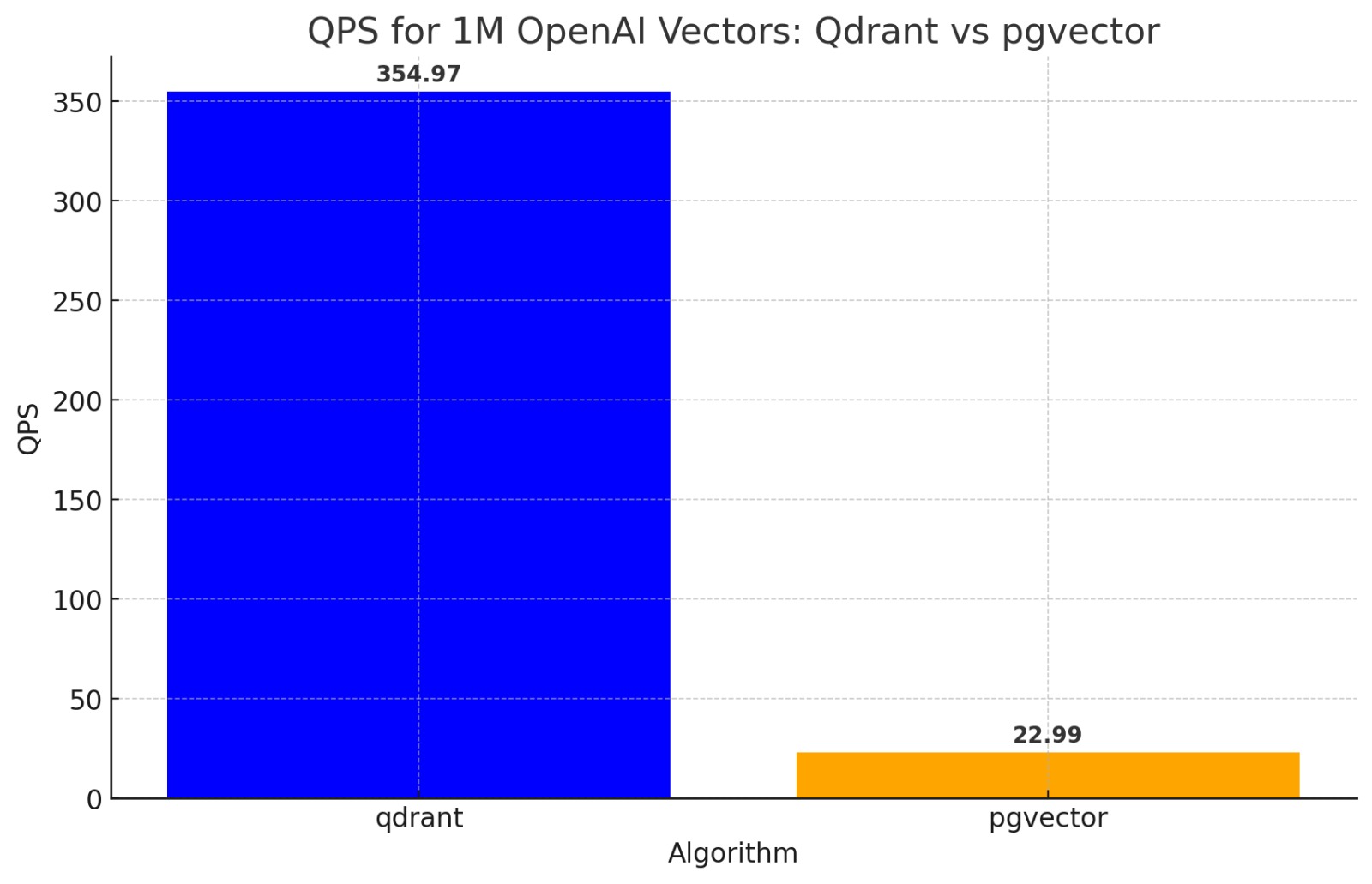
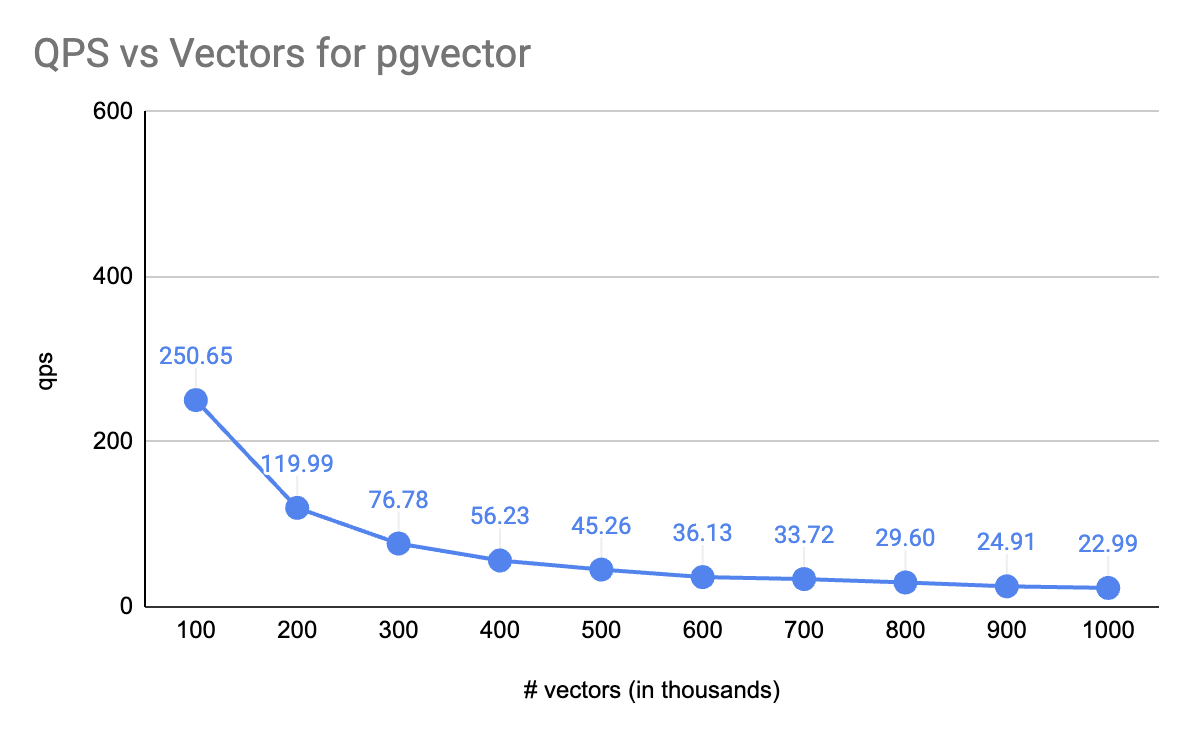
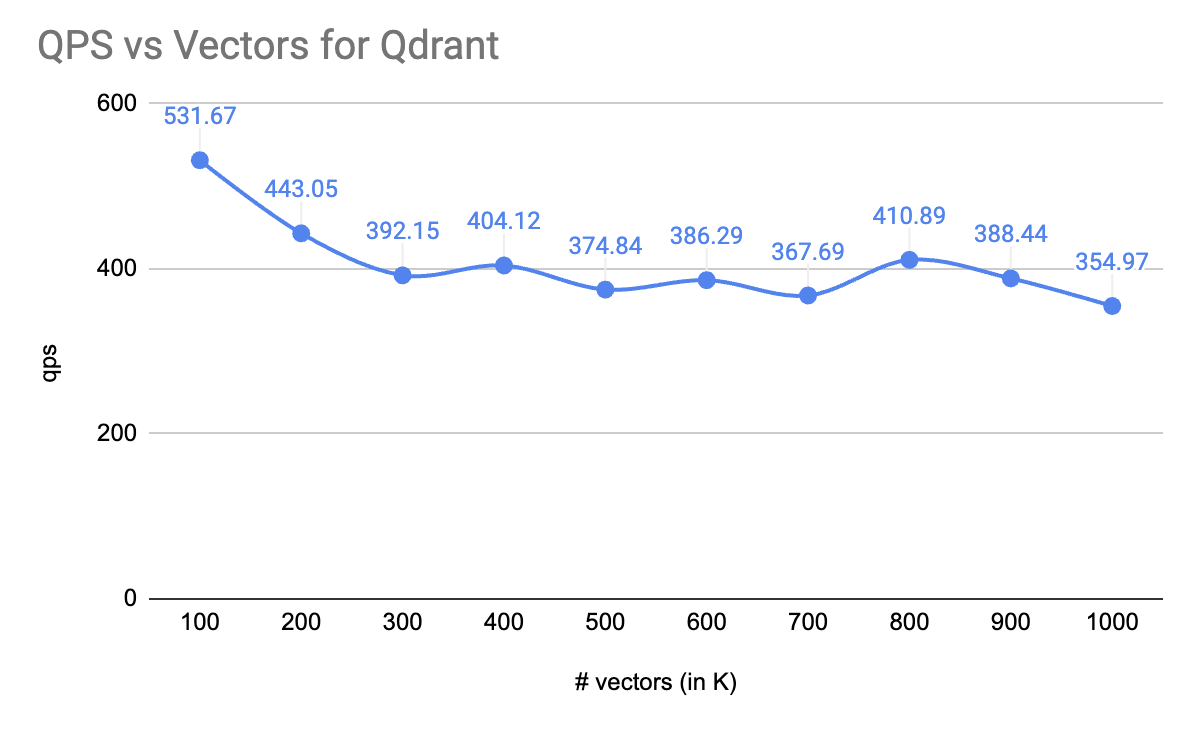
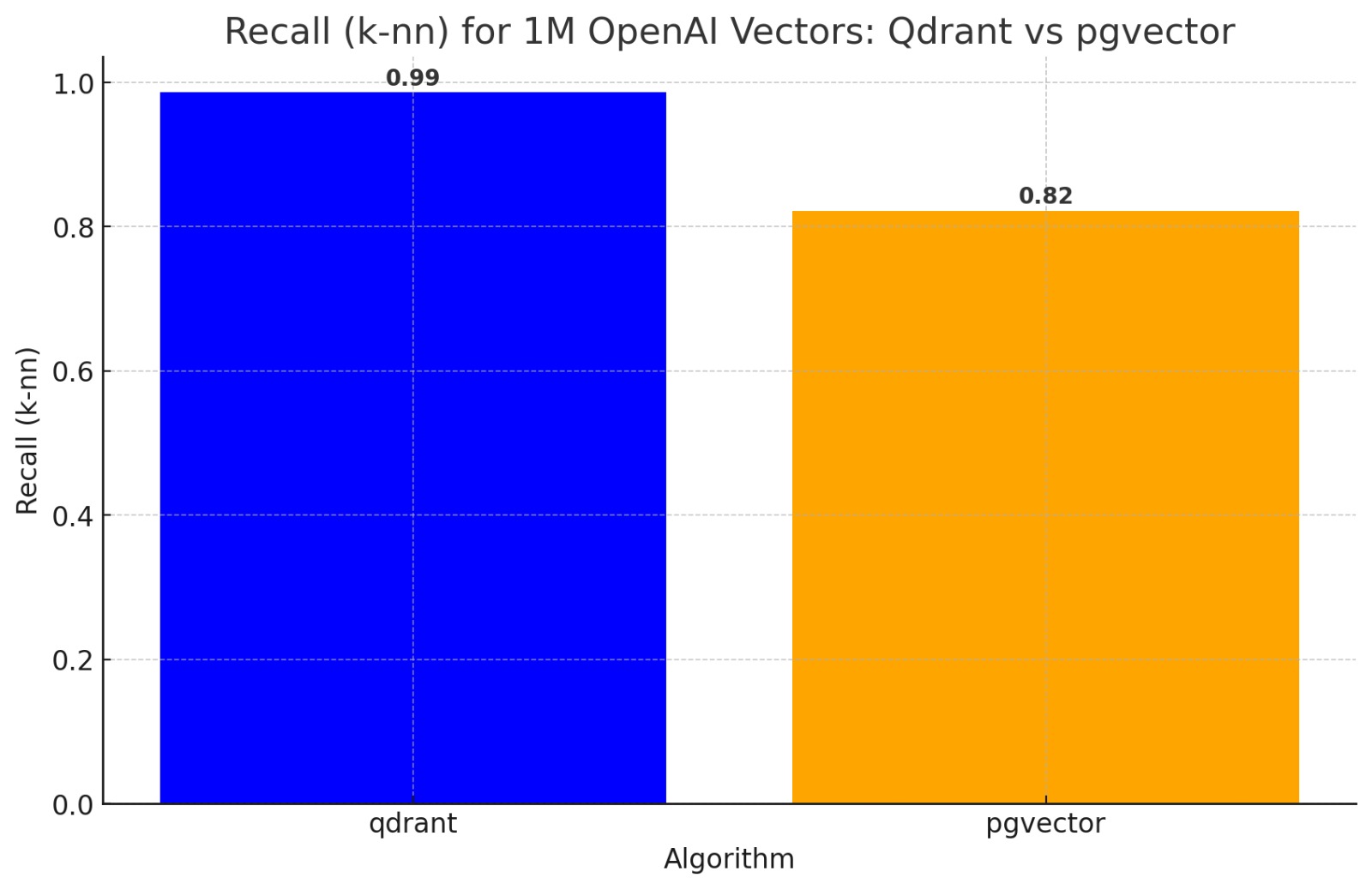
Bulk of this is borrowed from notes made my teammate and friend at Verloop.io's NLP/ML team of our conversations. I've taken the liberty to remove our internal slang and some boring stuff.
I want to build a community around me on NLP. How can I get discovered by others?
Broadly speaking, the aim in forming connections can be split into Long Term and Short term. A short term aim would be where you can receive something immediate out of the connections or a particular connection itself. This could be a collaboration, correspondence, recommendation/advice or anything else.
A more long-term, strategic aim would be a well defined long term goal that requires multiple steps to achieve. A strategic aim could involve multiple tactical steps. This is also, what we like to call friendship in some polite-speak areas of the world.
I have no immediate goals or projects, just need some basic ideas on how to be a part of the ML community.
Find interests of people and do something for them. Many people simply ask questions on Twitter, or you can infer what they are interested in looking at their Linkedin/work and their personal blogs.
What would be a good starting point for this?
A very easy thing to start with is literature review. Specially, for new topics being researched by influential people in the field. A good literature review shows your interest and willingness to help. Opens door to communication.
A good place to find what topics are missing a decent literature review: Go through NLP reddit r/LanguageTechnology or subreddits for Deep Learning, Machine Learning and so on.
Or go through twitter. And help people out there. Answer their question with depth. Do not rush to be the first, but the best. When it comes to technology, almost all platforms behave a bit like StackOverflow, the right answer might not get accepted: but it'll get noticed. Btw, lot of the Huggingface contributors happen to be active on Github and Twitter both. Hanging around on their Slack can't hurt either.
But important thing, try and stick to one medium. The place where you are most at home and gels with your personality. This could actually even be Youtube if you're an English-fluent, attractive looking person.
The other reason you need to stick to one medium is that audience will spend most of their time on 1 or 2 social media channels.
If they see that your content is not that popular on the other channel - They will do the cross posting for you. For instance, we've both seen Twitter content even within ML such as the Gary Marcus debate and attack on Yann LeCun spill over on reddit. And of course, people are still posting Tweets on TikTok!
Word of mouth will be your biggest friend.
Find problems that many people face. Usually a simple problem faced by many is a great problem statement. The python requests library comes to my mind as an excellent example of such a challenge. The work by gensim around shallow vectorization methods like word2vec and Glove was also quite similar in vein for quite a lot of time. Of course, with the rise of Deep Learning and better tooling makes their work less important - but they stuck in my mind, didn't they?
Why is that a great problem statement?
It's maximising the area under the curve. Solve a trivial problem faced by many or a huge problem faced by some. It has the same impact.
What's something that has worked for you in finding interesting problems?
Find intersections with domains that have little to do with each other. For us, there are domains that have little to do with tech/code and can see great benefits from our involvement.
Marketing yourself has nothing to do with marketing but everything to do with the problems you solve and the solutions you come up with. Make sure the solution is accessible to the wider audience. It should not be that only a certain section of the population can use it. If you plan to market yourself, spend 95% of the time on a quality problem and a quality solution and 5% of time talking about it. This is usually enough if the first 95% is done well.
What medium to talk about these in?
The usual are the blog posts or social media posts etc. But there is an open secret within the community. Writing papers is probably the best way to talk about stuff you’ve done.
Why so?
Papers have the halo effect. It improves your reputation and makes it sticky. People might forget a blog post quickly but you can get recognition/perks for around 2 years or so after writing a paper. There are other secondary gains too from doing this. Once you write a paper, you start reading papers differently. You have a better intuition of reading between the lines to understand the author’s intent/pov. Another obvious benefit is you get better at writing papers. Your thought process will start coming across much more clearly.