Retrieval Augmented Generation Best Practices
Retrieval and Ranking Matter!
Chunking
- Including section title in your chunks improves that, so does keywords from the documents
- Different token-efficient separators in your chunks e.g. ### is a single token in GPT
Examples
- Few examples are better than no examples
- Examples at the start and end have the highest weight, the middle ones are kinda forgotten by the LLM
Re Rankers
Latency permitting — use a ReRanker — Cohere, Sentence Transformers and BGE have decent ones out of the box
Embedding
Use the right embedding for the right problem:
GTE, BGE are best for most support, sales, and FAQ kind of applications.
OpenAI is the easiest for Code Embedding to use.
e5 family does outside English and Chinese
If you can, finetune the embedding to your domain — takes about 20 minutes on a modern laptop or Colab notebook, improves recall by upto 30-50%
Evaluation
Evaluation Driven Development makes your entire "dev" iteration much faster.
Think of these as the "running the code to see if it works"
Strongly recommend using Ragas for something like this. They've Langchain and Llama Index integrations too which are great for real world scenarios.
Scaling
LLM Reliability
Have a failover LLM for when your primary LLM is down, slow or just not working well. Can you switch to a different LLM in 1 minute or less automatically?
Vector Store
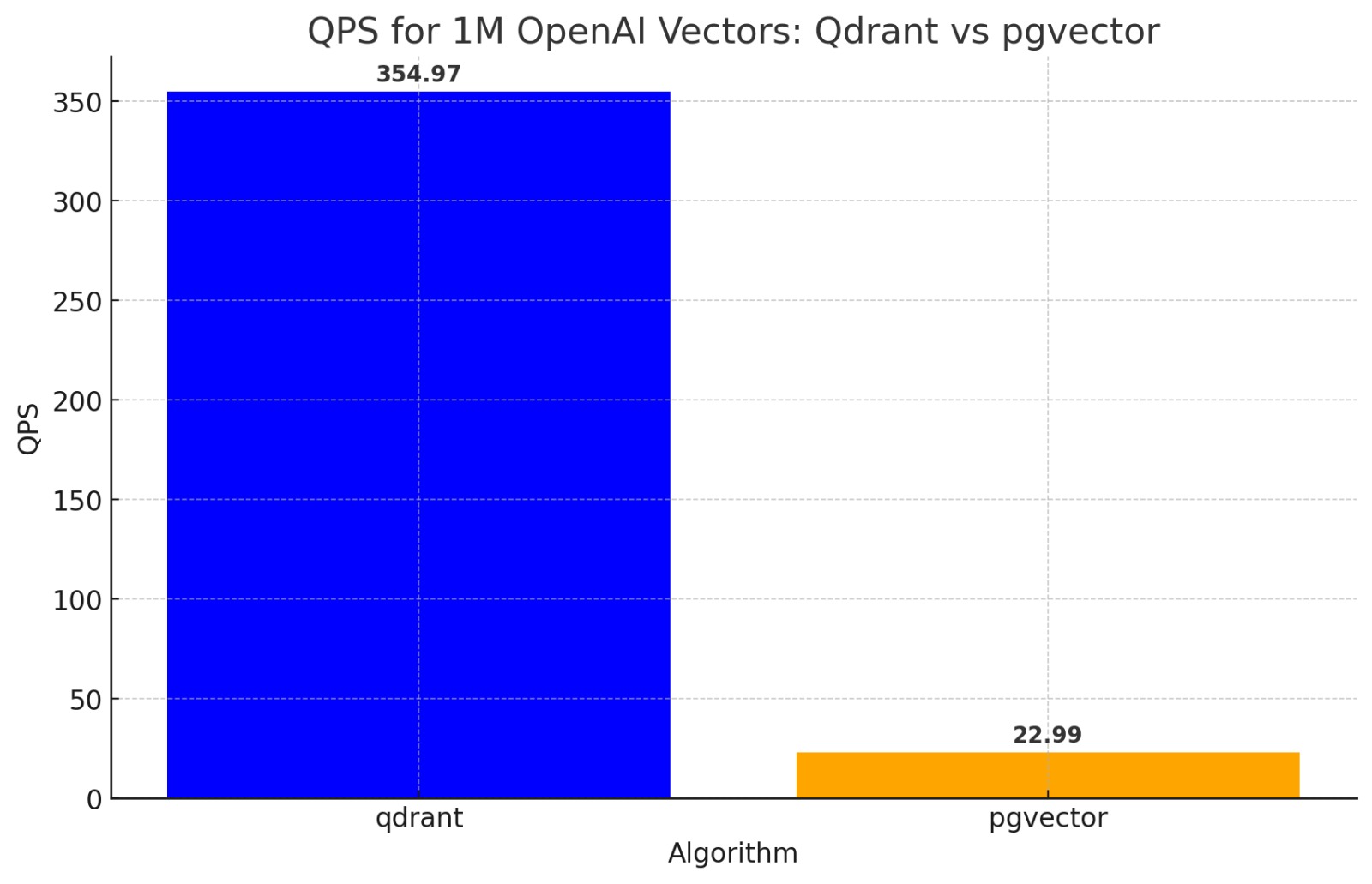
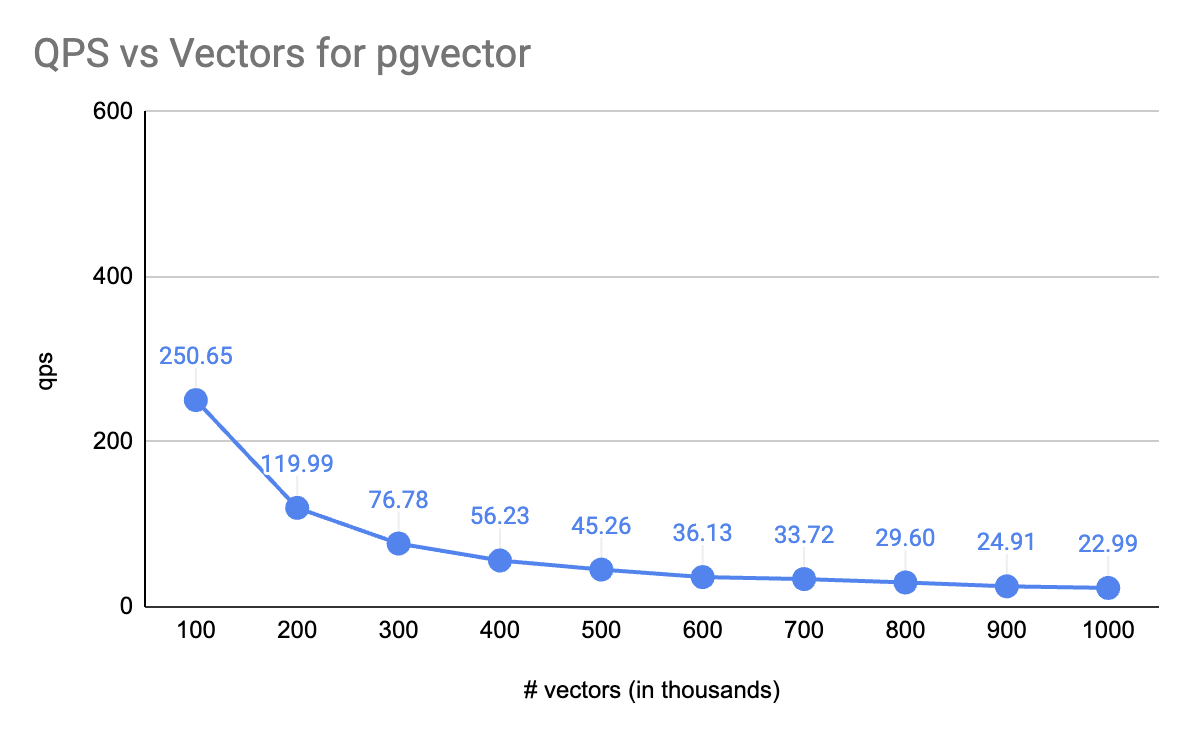
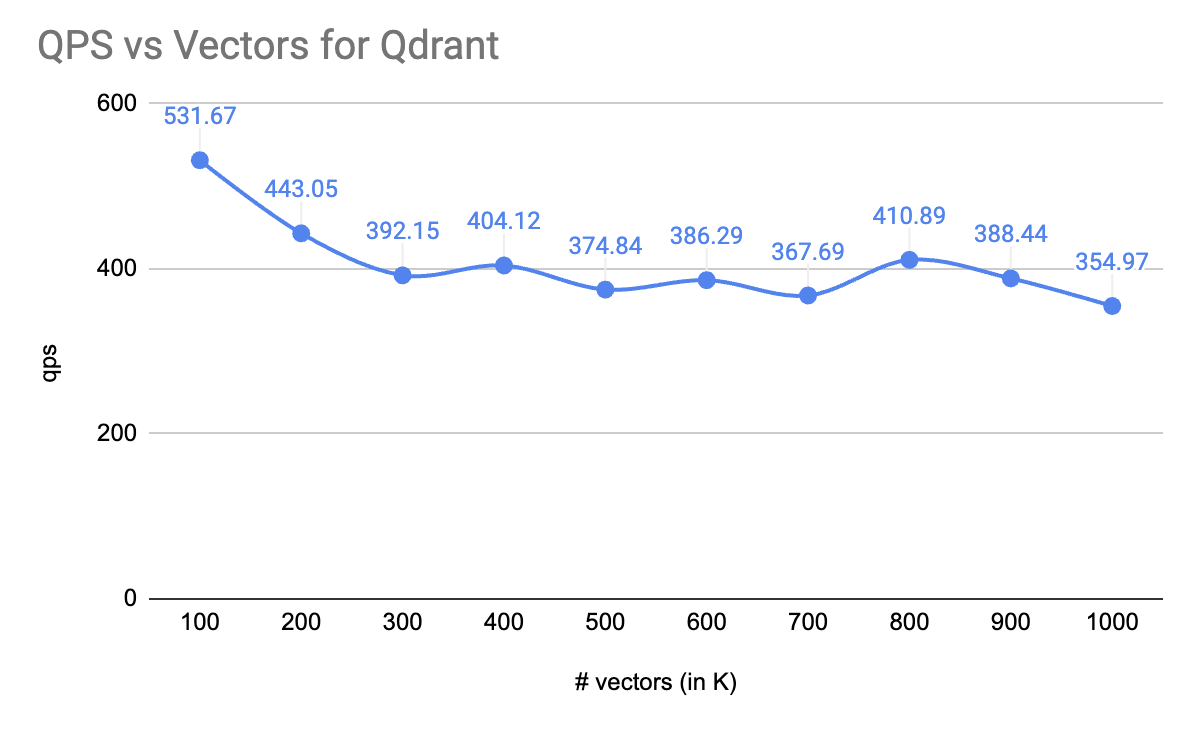
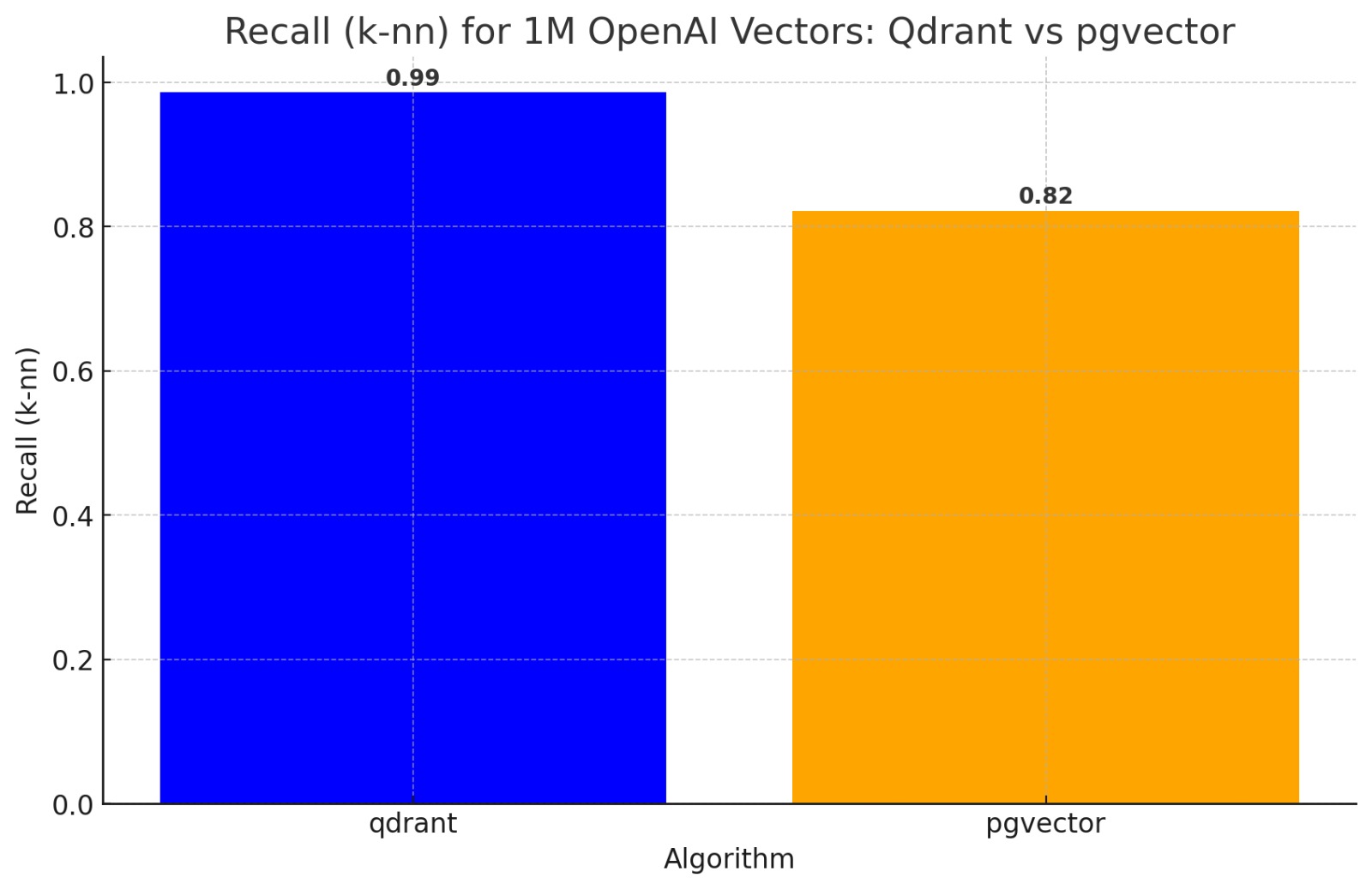
When you're hitting latency and throughput limits on the Vector Store, consider using scalar quantization with a dedicated vector store like Qdrant or Weaviate
Qdrant also has Binary Quantization which allows you to scale 30-40x with OpenAI Embeddings.
Finetuning
LLM: OpenAI GPT3.5 will often be as good as GPT4 with finetuning.
Needs about 100 records and you get the 30% latency improvements for free
So quite often worth the effort!
This extends to OSS LLM models. Can't hurt to "pretrain" finetune your Mistral or Zephyr7B for $5