Airbnb's Metric Store: Minerva
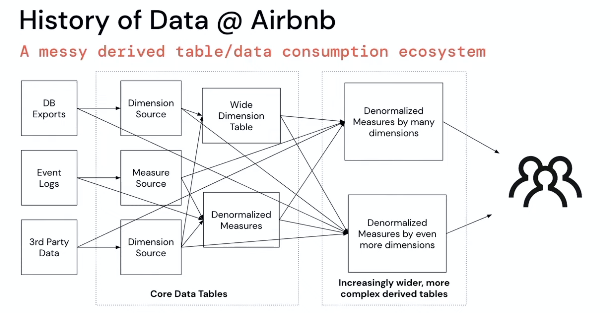
Data lineage is a problem because most companies have several tables and queries before humans consume it!
This has well known challenges: changes do not propagate downstream from the source, and reliable (fresh, updated or complete) data is not always available.
What does Minerva do?
I was expecting Minerva to a database (collection of tables), but it turns out that Minerva is what I'll call: Data Transformation Manager.
It overlaps quite a bit with dbt but it's not a pure execution layer. It also stores metadata, orchestrates the DAG itself, and provides a way to query the data (Hive/Druid here)

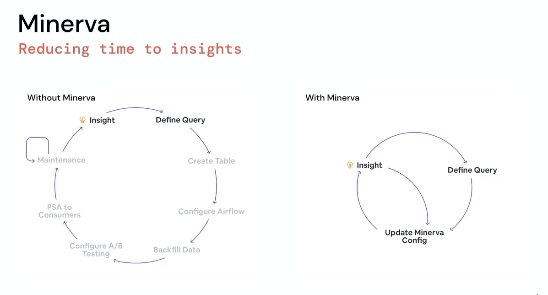
Minerva solves for one major problem in the analytics space: Time to insights — as [[Julie Zhuo]] has mentioned several times at Sundial
Minerva 1.0
This is a bit preview about the past and what problems did they first solve, what was left undone and some tooling/technology choices.
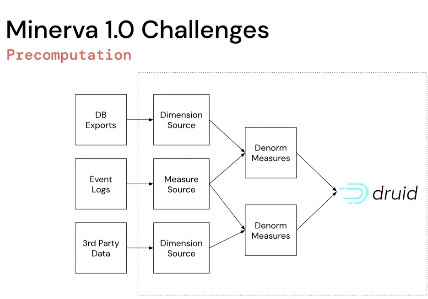
Pre-computation engine
Quite similar to how we were building Sundial till very recently.
- De-normed measures and dimensions
- Segments and behaviours were both separated out
De-norming measures can be quite expensive but useful. We converged to this design across multiple clients while working with Event-level data. We also see some of our clients maintaining a similar table: "User Segments Table".
Tradeoffs in the Precomputing Approach
- Cubing — SQL Minerva already knows what SQL query to run, across what segments and what durations upfront. This means it can leverage CUBE operations.
Some people believe that OLAP CUBE has fallen out of use, but that's clearly not true here. As companies get larger, "old" pressures on compute and storage should re-appear and so should already known solutions like cubing.
-
Fast Query Time: Since the results are precomputed - fast at query time
-
Exponential in query cost. Backfill — damn expensive and wastes time and money

Everything has to be asked ahead of time, so you end up calculating too many things
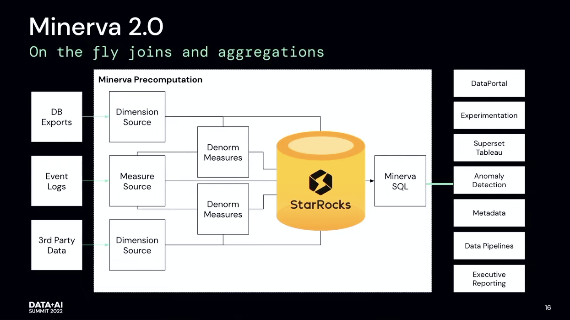
Minerva 2.0
This is what a truly "modern" data transformation manager should look like in my opinion.
Here are some of the design choices:
- On the fly joins
- On the fly aggregations
- Optional denorm and cubing
- Enable precompute to be turned on
The way I see it, this is striking a balance between flexibility (the ability to do on-the-fly joins and aggregations) and cost (the ability to precompute with denorm and cubing).
Engineering Choices
Moved from Druid to StarRocks
Why StarRocks?
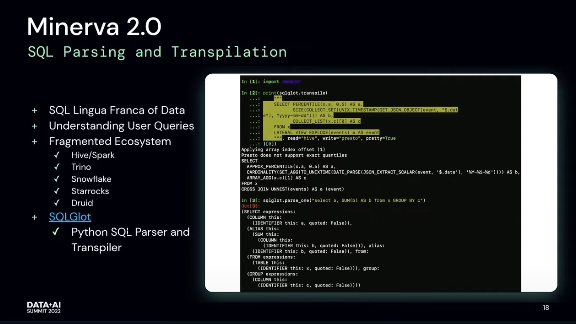
Minerva is SQL generation tool, not a Druid ingestion tool
Minerva has a SQL Interface now, early was JSON

SQLGlot — Python SQL Parser and Transpiler -- this is very similar to dbt for how it generates SQL using a parser and transpiler. SQLGlot is open source btw: https://github.com/tobymao/sqlglot
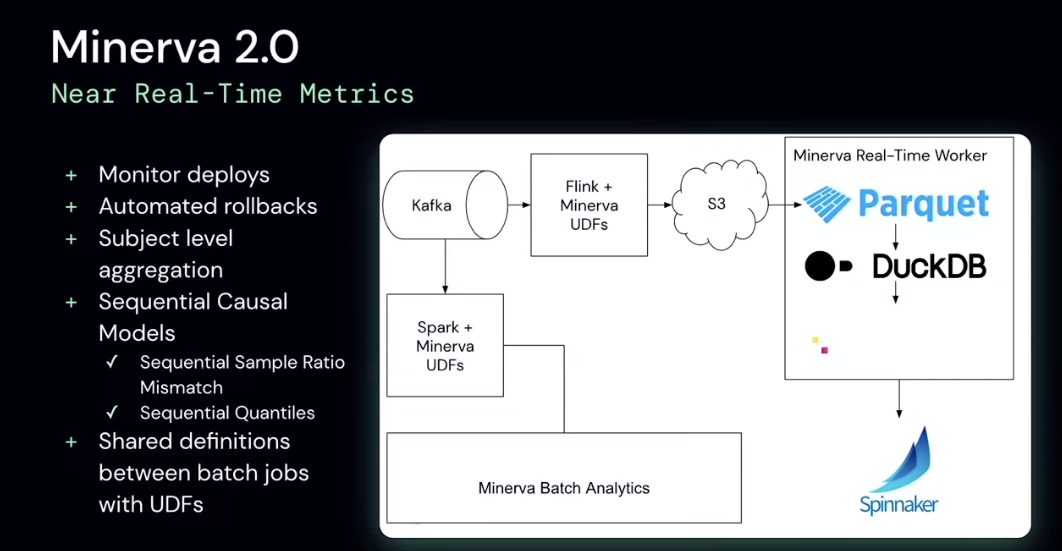
Near Real Time Metrics
Summary of changes made for 2.0 release

Major changes is that SQL is now a first class citizen
This is quite important. We should resist the temptation of inventing a Python transformation layer/logic. While some Python is inevitable for doing more interesting things like forecasting, using Python for calculating ratios is a bit overkill. We should instead try and consider pushing the limits of SQL for the same.
SQL is not only more widely spoken, it'd be a lot more efficient and more scalable. The downside? It's less general purpose language, and we'd have to write some tooling to make SQL work like Python.
These are some notes and screen grabs from a talk which I'd found on Youtube. Thanks to Kunal Kundu for finding the talk link which I'd lost!